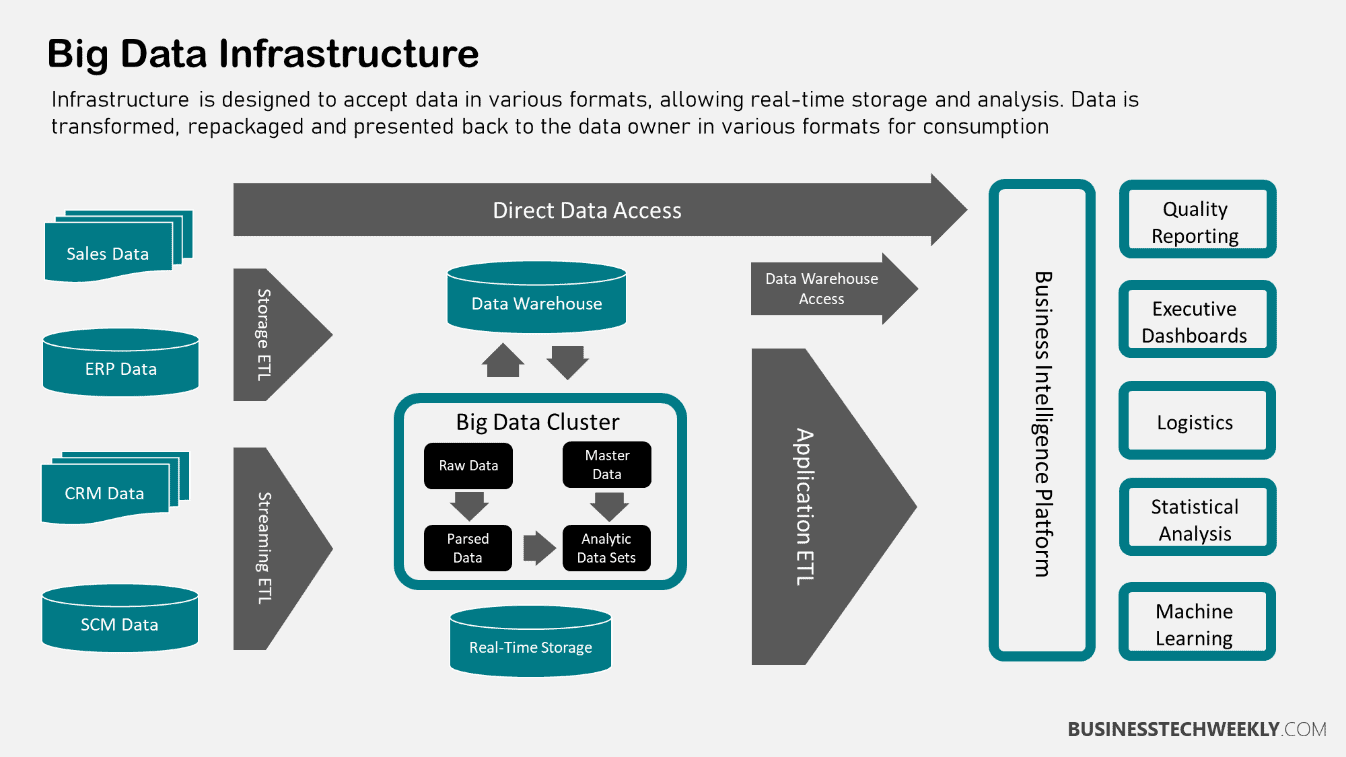
Understanding Big Data Infrastructure – A Complete Guide

A Big Data environment should allow storing, analyzing, and processing data. Making the most of your data not only involves selecting the right set of tools and processes but also ensuring the right big data infrastructure and technologies are deployed.
Infrastructure is a valuable component of the Big Data ecosystem. It entails the tools used to gather data, the physical storage media used to store data, the software systems utilized, the applications handling it, the analytic tools that process it, and the network that transfers it.
Below, we provide an overview of big data infrastructure and the common technologies it comprises so that you can easily build one for your big data project.
What is Big Data Infrastructure?
As the name suggests, Big Data infrastructure is the IT infrastructure that hosts big data. Specifically, it is a critical part of the big data ecosystem bringing together different tools and technologies used to handle data throughout its lifecycle, from collection and storage to analysis and backup.
Related: Understanding Big Data
Enterprises relied on traditional databases for decades to process structured data. However, the volume, velocity, and variety of data mean these databases can often fail to deliver the latency and reliability to handle more complex, bigger data.
The rise of unstructured data specifically suggested that data storage required something beyond rows and tables.
New infrastructural technologies thus emerged with the capability of handling a vast variety of data, making it easy to run applications on large systems involving massive volumes of information. These new technologies have low latency, low cost, and high scalability and are often open-source.

Key Components of the Big Data Infrastructure
Most enterprises use a combination of infrastructural technologies in their big data environment. Let us talk about the fundamental approaches used for big data projects, how they work and what situations they best suit.
Hadoop
An open-source framework that has revolutionized the entire data storage and computation space, Hadoop is designed to be a complete ecosystem of technologies for data storage, analysis, and processing.
The fundamental principle behind the working of this technology is to break up and distribute data into parts and analyze and process different parts concurrently rather than handling one block of data at once.
Hadoop provides vast storage of data, structured and unstructured, great processing power and the ability to handle endless concurrent tasks.
Leveraging computing power enables companies to analyze big data sets in a scalable way using open source software and cost-effective hardware.
The primary benefits of Hadoop are:
- Flexibility – Unlike relational databases, there is no need to process data before storage. Hadoop allows storing as much data as you would like and deciding how to use it. This also includes unstructured data, including images, videos, and text.
- Speed – As it processes multiple parts of the data set simultaneously, it is a significantly fast tool for in-depth data analysis.
- Scalability – Hadoop, unlike traditional systems with limited data storage, operates in a distributed environment and is scalable. It is easy to grow the system to handle more data by simply adding more nodes.
- Computing Power – Hadoop uses a distributed computing model that quickly processes big data. More computers can be added to scale the system to increase processing power.
- Low Cost – This open-source framework is free to use and stores vast amounts of data on commodity hardware.
- Resilience – The distributed framework is resilient. Data stored on a node gets replicated on other cluster nodes to deal with hardware or software failures. Such a design ensures fault tolerance; there is always a backup available if a node is down.
Some crucial components of the Hadoop ecosystem include:
- HDFS – It is the default file system that allows large data sets to be stored in a cluster
- YARN – It is responsible for the scheduling of user applications and cluster management
- MapReduce – It is a big data processing engine and programming model that facilitates the parallel processing of data sets
- Hadoop Common – It provides a set of services across utilities and libraries to support other modules

NOSQL
NoSQL stands for Not Only SQL and is a term that refers to a variety of database technologies. NoSQL works around the concept of distributed databases, where unstructured data can be stored across multiple nodes and even across servers.
This type of database allows agile, high-performance data processing at a big scale. Unlike relational databases, they can handle dynamic, unstructured data with low latency, making them ideal for big data systems.
Such a distributed framework means these databases are scalable; you can keep adding more hardware as data volume increases.
This database infrastructure has served as the solution to some of the biggest data warehouses, including Amazon and Google. Some of the most popular NoSQL databases come from Apache and Oracle. Most of the widely used databases of this kind are open-source.
Here are the four primary types of NoSQL databases.
- Key-Value Stores – The most straightforward model to implement, key-value pair database stores data as a hash table where every key is unique and the value can be a number, string, or anything else.
- Column Family Stores – Such systems are designed to store and process large data distributed over machines. Keys point to multiple columns grouped into families. Column-based databases are used for CRM, business intelligence, and data warehouses.
- Document Databases – These models are generally collections of other key-value collections. They are like the next level of key-value and allow nested values for each key. They provide better efficiency for querying.
- Graph Databases – This type of database uses a flexible graph model, which can scale across machines. Querying of such databases is data-model specific. A graph-based database is multi-relational, allowing fast traversing of relationships. Such systems are generally used for logistics and social media networks.
Let us look at the primary benefits of using NoSQL databases.
- Data Processing – These databases follow a scale-out architecture where scalability is achieved by distributing data storage and processing over a cluster of computers. When you want to increase the capacity, more computers are added.
- Support – NoSQL databases allow storing data comprehensively, whether you are working with structured, semi-structured, or unstructured data.
- Easy Updates – These databases allow developers to change the data structure with zero downtime easily. The addition of new values and columns can be performed without disrupting the current structure.
Massively Parallel Processing (MPP)
Massively Parallel Processing or MPP are computational database platforms capable of processing data at incredible speeds. In such a framework, hundreds and thousands of processors work on different parts of the program, each having its memory and operating system.
The basic functionality uses the concept of data segmenting and involves creating chunks of data across nodes and processing them in parallel.
MPP is quite similar to Hadoop in segmenting and concurrent processing on nodes. However, it is different as it doesn’t execute on commodity hardware.
Instead, these systems work on specialized, high-memory components. They feature an SQL-style interface for data retrieval, and they generally process data faster with the use of in-memory processing.
Data warehouse appliances typically used for big data analysis use this architecture for high performance and easy scalability.
Some of the benefits of deploying an MPP architecture are:
- Elasticity – It is easy to add nodes without rendering the cluster unavailable.
- Cost-efficiency – With this framework, there is no need to invest in any expensive hardware to take care of tasks. By adding more nodes, the workload is distributed, which can be easily handled with cost-effective hardware.
- Reliability – This type of database system also eliminates a single point of failure. When one node fails, others remain active and continue working until the failed node is repaired.
- Scalability – With MPP databases, there are endless ways to scale. These systems allow adding nodes to store and process significant volumes of data as required.
![Big Data Infrastructure Benefits]() Cloud Computing
Cloud Computing
 Cloud Computing
Cloud ComputingCloud computing covers a set of services delivered over a network.
While other approaches to big data infrastructure require buying hardware and software for each individual involved in the processing and analyzing data, this type of database is available as a web-based service that gives access to all the programs and resources. Upfront costs are generally low for cloud computing because you only pay for what you use and scale up as needed.
Related: Understanding Cloud Services: What is cloud computing?
Cloud also has the benefit of delivering speedier insights. Though hosting data on a third-party network can raise security concerns, organizations generally prefer hosting sensitive information in-house while using the cloud for less confidential data.
Several big names in the IT landscape offer cloud computing solutions. For example, Google has a wide range of products, including BigQuery, designed especially for handling big data.
Some of the advantages of using cloud computing for big data infrastructure are:
- Reduced Complexity – A big data implementation demands multiple integrations and components. With cloud computing, much of the integration can be automated, minimizing complexity and improving team productivity.
- Cost Cutting – Cloud computing is an excellent choice for enterprises looking to run their operations on a budget. With this option, companies can avoid the expenses associated with installing and maintaining hardware. The responsibility shifts to cloud providers, and you pay only the service charge.
- Agility – With this technology, it is easy to set up infrastructure instantly, whereas traditional methods make it quite time-consuming and expensive. Cloud-based big data platforms make the process easy and accessible regardless of the type and size of the business.
Cloud computing provides an option to store vast amounts of data, allowing big data to be scalable, available, and fault-tolerant.
Big Data Infrastructure: Final Thoughts
As big data technologies continue to mature, there is no doubt these technologies and approaches will become central to allowing businesses to reach their full potential with massive amounts of data.
Though adoption of such technologies can be expensive, companies find it a worthy investment considering the value big data brings to the table.